Machine Learning
K-Nearest Neighbor(KNN) Algorithm for Machine Learning




K-Nearest Neighbor(KNN) Algorithm for Machine Learning
- K-Nearest Neighbour is one of the simplest Machine Learning algorithms based on Supervised Learning techniques.
- K-NN algorithm assumes the similarity between the new case/data and available cases and put the new case into the category that is most similar to the available categories.
- K-NN algorithm stores all the available data and classifies a new data point based on the similarity. This means when new data appears then it can be easily classified into a good suite category by using K- NN algorithm.
- K-NN algorithm can be used for Regression as well as for Classification but mostly it is used for the Classification problems.
- K-NN is a non-parametric algorithm, which means it does not make any assumption on underlying data.
- It is also called a lazy learner algorithm because it does not learn from the training set immediately instead it stores the dataset and at the time of classification, it performs an action on the dataset.
- KNN algorithm at the training phase just stores the dataset and when it gets new data, then it classifies that data into a category that is much similar to the new data.
- Example: Suppose, we have an image of a creature that looks similar to a cat and a dog, but we want to know whether it is a cat or a dog. So for this identification, we can use the KNN algorithm, as it works on a similarity measure. Our KNN model will find the similar features of the new data set to the cats and dog’s images and based on the most similar features it will put it in either the cat or dog category.
Why do we need a K-NN Algorithm?
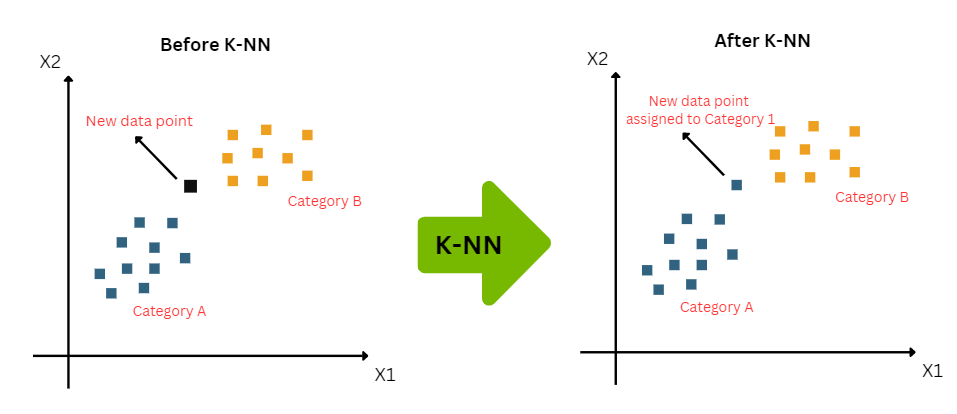
Suppose there are two categories, i.e., Category A and Category B, and we have a new data point x1, so this data point will lie in which of these categories? To solve this type of problem, we need a K-NN algorithm. With the help of K-NN, we can easily identify the category or class of a particular dataset. Consider the below diagram:
How does K-NN work?
The K-NN working can be explained on the basis of the below algorithm:
- Step-1: Select the number K of the neighbors
- Step-2: Calculate the Euclidean distance of K number of neighbors
- Step-3: Take the K nearest neighbors as per the calculated Euclidean distance.
- Step-4: Among these k neighbors, count the number of the data points in each category.
- Step-5: Assign the new data points to that category for which the number of neighbors is maximum.
- Step-6: Our model is ready.
Suppose we have a new data point and we need to put it in the required category. Consider the below image:
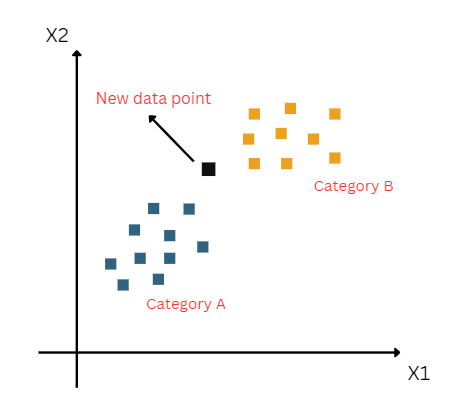
- First, we will choose the number of neighbors so that we will choose the k=5.
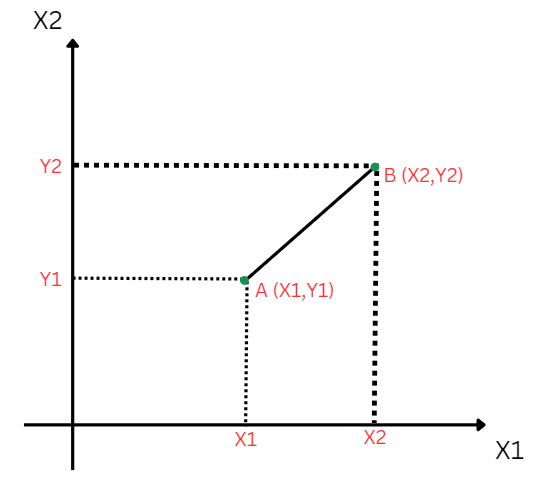
- Next, we will calculate the Euclidean distance between the data points. The Euclidean distance is the distance between two points, which we have already studied in geometry. It can be calculated as:
- By calculating the Euclidean distance we got the nearest neighbors, as the three nearest neighbors in category A and the two nearest neighbors in category B. Consider the below image:
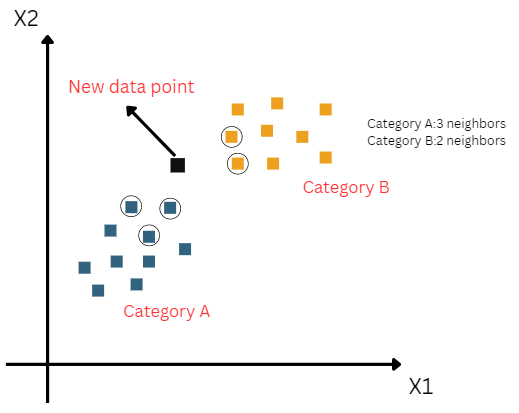
- As we can see the 3 nearest neighbors are from category A, hence this new data point must belong to category A.
Why Value of K is Important ?
K affects the accuracy of our model and the number of nearest neighbors from which our new data is classified is highly significant very small value for K could lead to overfitting and a very small value for k could lead to underfitting. So, Choosing the right value for K is very important
How to select the value of K in the K-NN Algorithm?
Below are some points to remember while selecting the value of K in the K-NN algorithm:
- There is no particular way to determine the best value for " K", so we need to try some values to find the best out of them. The most preferred value for K is 5.
- A very low value for K such as K=1 or K=2, can be noisy and lead to the effects of outliers in the model.
- Large values for K are good, but it may find some difficulties.
KNN Algorithm Selection:
In scikit-Learn,when building a KNeighborsClassifier without specifying the algorithm parameter, it defaults to algorithm=”auto”. This is a smart setting that allows scikit-learn to automatically select the k based on the nature of data.
There are four types of algorithm behind KNN
1. Brute Force ( algorithm=”brute”)
- The brute force in KNN calculates the distance between the query point and each point in the dataset and then it sorts these distances and finds the nearest neighbors.This method is simple , straightforward and doesn’t rely on any special data structure for efficient searching
- It is best for small datasets where the computational cost for each point is manageable. Brute force provides flexibility by computing the exact distances without depending on specific data structures
- The main drawback of the brute force is that it becomes very slow as the dataset size increases.In high-dimensional and large datasets , the computational time increases since it requires to calculate distances to every data point.
2. KD – Tree ( algorithm=”kd_tree”)
- The KD-Tree (k-dimensional data) is a space-partitioning data structure that divides the dataset into regions along the feature axes.At each level of the tree,the data is split into two subsets based on a selected axis and this process is repeated recursively.These splitting allows algorithm to search for nearest neighbors more efficiently portions of irrelevant data.
- KD Tree is particularly for low- dimensional data (<20) features.In such cases KD Tree excels by reducing the number of comparisons required during the search process and making it to faster than Brute force
- The main drawback of KD Tree is the performance reduces in high dimensional spaces. As the number of features increases ,the partition becomes less effective and the search time approaches that of brute force.This is due to curse of dimensionality where data is evenly distributed and make space partitioning less efficient
3. Ball Tree ( algorithm = "ball_tree" )
- Ball Tree is another space-partitioning data structure that arranges data points into a tree of nested hyper-spheres (balls), rather than axis-aligned areas as in KD-Tree.
- It creates a binary tree by recursively dividing the data into two parts. Each node in the tree contains a ball that surrounds a subset of points.
- This technique outperforms KD-Tree with medium- to high-dimensional data since it does not rely on axis-aligned splits.
- It is generally more efficient than brute force for larger datasets with higher dimensions. Ball Tree is more adaptable to managing different distance measurements, such as Manhattan, Minkowski, and so on.
Advantages of KNN Algorithm:
- It is simple to implement.
- It is robust to the noisy training data
- It can be more effective if the training data is large.
Disadvantages of KNN Algorithm:
- Always needs to determine the value of K which may be complex sometimes.
- The computation cost is high because of calculating the distance between the data points for all the training samples.
about the author
Sumer Pasha
Sumer Pasha is a Python Automation Engineer with Analogica India. He is a python developer and uses python to develop internal utilities for Analogica.
